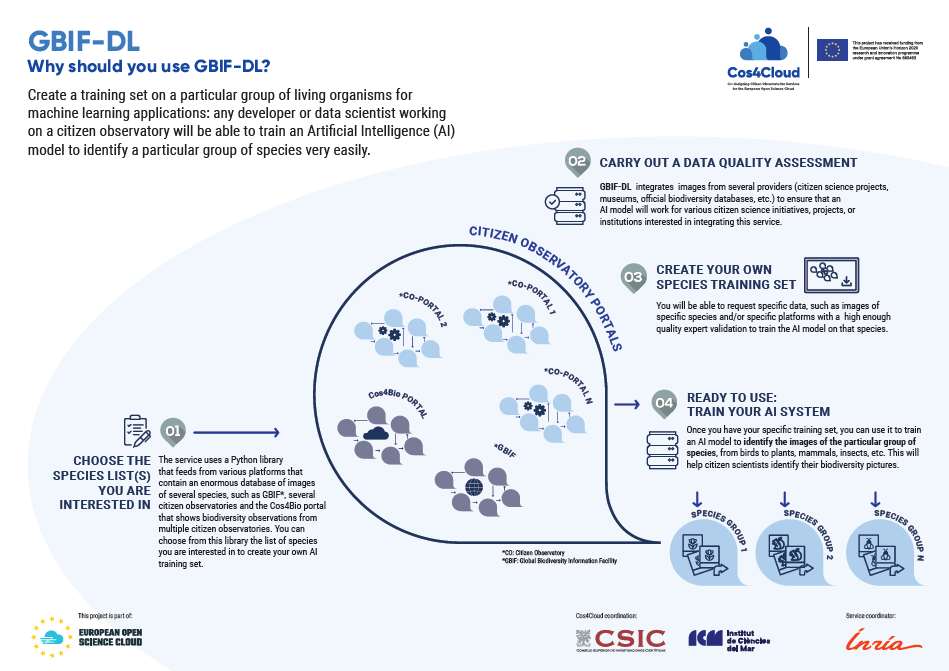
GBIF-DL: Create a training set on a particular group of living organisms for machine learning applications: any developer or data scientist working on a citizen observatory will be able to train an Artificial Intelligence (AI) model to identify a particular group of species very easily.
Service description:
Service that allows users to create a training set on a particular group of living organisms on-demand, i.e. allowing them to solicit specific data, such as images of specific species and/or specific platforms, or images with a sufficient quality of expert validation.
Example: A data scientist or a developer who wants to train an artificial intelligence model on a particular group of species using pytorch software will be able to do it very easily.
Main features:
- Media retrieval: The main feature of GBIF-DL is to retrieve media URLs from Global Biodiversity Information Facility (GBIF). In particular, it supports two ways to retrieve image URLs: (1) one is to query the GBIF-DL API’s module directly. This is suited for quickly retrieving smaller datasets that do not require extensive query parameters. (2) Another way is to use already the GBIF download workflows, which assemble a Darwin Core Archives waiting on the GBIF servers. The query supports all fields that are supported by the GBIF occurrence API.
- Balancing items: Very often, users won’t be using all media downloads from a given query list of species since this often results in datasets with a heavily imbalanced number of samples per label. When generating URLs from the API, users can specify specific additional attributes to influence the sampling process. For example, the dataset can simultaneously be balanced by the provider and by species. This will allow downloading a similar number of media items from each provider and for each target species.
- Get URLs using Darwin Core Archives: A URL generator can also be created from a GBIF download link given a registered DOI or a GBIF download ID.
- Compatibility with Pytorch and TensorFlow: GBIF-DL makes it simple to train a PyTorch image or TensorFlow classification model based on the downloaded training set.
- Quality of service: Several features of GBIF-DL ensure a good quality of service. This includes:
- High downloading performance via multi-threading fall-back
- Return download statistics on the flight
- Logging of downloading errors and improved procedure to restart the download of missed images
- Log image licensing information to make the service PEDR compliant
Innovation for citizen observatories:
The service will allow for the aggregation of massive sets of image data related to large groups of species, using the APIs of several platforms and citizen observatories, in order to facilitate learning by efficient AI models for automated identification.
There is nothing similar available.
Questions & answers:
- Who is this service meant for? Do I need a technical background?
Developers or data scientists with some background in data engineering and Python language.
- Can I choose which source I want to extract the training list from, e.g. iNaturalist?
Yes, you can specify one or several GBIF data publishers.
- Can I integrate this service into existing apps?
Yes, you can integrate Biodiversity-DL into your own workflow (under the MIT open-source licence).
- Can I create lists of both plant and animal species?
Yes, you can create both animal and plant species lists.
- Can I create as many lists as I want?
Yes, there is no limit. You can create as many training sets as you need.
Keywords:
Artificial Intelligence, AI, training data, data quality, species identification, biodiversity data.
Guidelines and documentation to use GBIF-DL:
Coordinator: